

近年、発展目覚ましい音声認識技術ですが、そもそもどうしてコンピュータが人間の声を認識できるのでしょうか?音声認識の仕組みについて解説します。
\利用社数2,600社以上!/
カイクラの詳細を見る
▲無料ダウンロード資料あり

【PR】次世代型電話業務DXツール「カイクラ」
- 継続率、驚異の99.8%
- 煩雑な電話業務が圧倒的にラクチンに
- 自動通話録音・文字起こし、AI要約でトラブル回避
\ 利用社数2,600社以上 /
公式サイトを見る
音声とは?
音声とは文字の通り声の音です。音は空気の振動ですが、声とは人間が声帯を震わせながら吐いた息であり、空気の振動の信号です。ただし発声は声帯に限らず喉や胸、腹、鼻、唇などを使う事もあるのでより厳密に定義するのなら「人間が発声器官を通じて発する音」だと言ったほうが適切です。
日本語に限らず英語や中国語など、どのような言語の話者でもこの原則は変わりません。

人間が音声を認識する仕組み
人間は主に鼓膜を使って空気の振動である音声をキャッチし、その周波数のパターンで話者や意味を認識します。耳はふさげないので大勢の人がいる場所では話している相手の声以外の様々な音が鼓膜を震わせていますが、無意識に不要な音をスクリーニングして聞こえないようにしています。
これを音声の選択的聴取、カクテルパーティ効果と呼びます。
カクテルパーティーのように、たくさんの人がそれぞれに雑談しているなかでも、自分が興味のある人の会話、噂、自分の名前など、自分にとって重要度が高いものは、無意識に聞き取れるのです。
しかも純粋に受け取った音の振動、周波数をスクリーニングするだけでなく、たとえ聞こえていなくても、相手が喋ったと思われる、あるいは喋る可能性が高い言葉を脳が勝手に補完する働きがあり、実際には発言していない言葉を聞いたように錯覚することがあります。
これを空耳と言います。
カクテルパーティ効果は主に聴覚についての説明原理ですが、同様の仕組みは視覚や味覚、触覚、嗅覚を含めた基本的な人間の認知の仕組みの全てに共通しています。
例えば視界に入るという事は眼球を通じて網膜に映像が写っているのですし、音声が聞こえるという事は鼓膜を震わす振動をキャッチしているという事です。更に付け加えるのならお菓子を食べながら映画を見ていたら、いつの間にか味も分からぬまま全部食べてしまっていたり、夢中になり過ぎてコーヒーをこぼしているのに気付かなかったという事もあります。
上記の例が示すように人間の感覚は絶対ではありません。センサー(神経)がキャッチしても無意識が重要だと思ったものしか意識に上がらないので、認識できないのです。
そんなハズはないと思われるかもしれませんが、誰しも写真を見直した時に撮影時には気が付かなかったものを見つけたり、宴会のビデオを再生したら思った以上にざわついていた、という実体験があるかと思います。
こうして目に映っているけど見えていないもの、聞こえているけど聞けていないものを心理学用語で盲点、スコトーマと呼びます。
本来、スコトーマとはギリシャ語で「盲点」を意味する眼科の用語ですが、近年は認知的盲点を指すのにも使われるようになりました。
カクテルパーティ効果はスコトーマの働きによってもたらされます。
無意識が重要性に応じてスクリーニングしてくれるからこそ、ひどい雑踏の中でも聞きたい人の声を聞き取れますが、重要性を認識していない物事については逆に聞こえないものも出てくるということです。
以上が人間が音声を認識する基本的な仕組みです。

コンピュータが音声を認識する仕組み
コンピュータも人間の仕組みを模して音声を認識しますが、大前提として音声認識には必ずテキスト化が含まれています。人の声を保存・再生するだけならボイスレコーダーと変わりません。音の波をテキストに変換する事で様々な活用が出来るのです。
コンピュータは人間が音を聞くアルゴリズムを模して、人間の鼓膜に当たるマイクで周囲の音を拾い、その中から人間の音声にあたる周波数だけをスクリーニングすることで音声を認識しテキストにします。そのためマイクの精度が悪かったり雑音が多い場所では読み取り精度が低下します。
人間とは違い、コンピュータにとっては人の声も雑音も同じ空気の振動に過ぎず、意識も無意識もないのでスコトーマがありません。従って重要度による認識精度のコントロールがないのです。
何の処理もしなければ、あくまでもマイクに伝わる音の振動は全て同じ重要度として処理されてしまいます。
つまり全ての音の重要度が同じに扱われるという事は認識したい相手の音声と雑音が混ざってしまうということです。そこで認識すべき人間の声とそうでないものを先に分ける必要があります。
人間の声は特定の周波数の信号パターンですが、これを約10万分の1秒の長さに区切ったものを音素と呼びます。これは声を扱う際の最小単位です。そして音素には個々人によってパターンがあり、これを音響モデル(周波数特性)と呼びます。コンピュータは音響モデルごとに誰が喋っているのか認識(話者認識)するのです。
合わせて事前に対象となる音声の音響モデルを学習させておけばより認識精度が向上します。
以上が周波数としての音をスクリーニングする方法ですが、音声認識は音響モデルだけではありません。他にも音声の読み取る方法も組み合わせています。
一つは辞書の作成です。あらかじめ該当する言語の辞書(日本語や英語など)を作っておく事で類似の音素と照らし合わせてテキストとして出力します。
辞書については様々なものがありますが、名古屋工業大学 Julius開発チームがオープンソースの辞書を公開しており、数万語彙が活用できます。条件はありますが商用利用も出来るとのことですから、地力で開発するのなら参考になるでしょう。
また言葉のパターンマッチングで一連の音が来たら次の音は何が来る可能性が高いか、類推して音を当てはめていく技術が盛り込まれています。
これを隠れマルコフモデルと呼びます。厳密に解説するには数式が必要なのでかなり大雑把な理解になりますが、人間でいうところの終わりまで聞く前に相手が次にいう事を予測する、という仕組みを分解してアルゴリズムとして活用するのです。
例えば「今日は天気が……」と続いたら、次の言葉は「良い」とか「雨」といった天気に関するものが選ばれる可能性が高いです。「今日は天気が…新宿駅」のような前段と関係の無い言葉が選ばれる可能性は低いので、聞き取りをしながら次に来るキーワードをデータベースから予想してリアルタイムで素早く処理します。
言葉の順番はランダムではありません。自由に喋っているつもりでも、意味が通る言葉には一定の規則性があるので確率的に次に選ばれる言葉の範囲を限定できるのです。
他にもAIを用いたディープラーニング(機械学習)で会話のモデルを蓄積して自然な受け答えが出来るように学習が進んでいます。現時点における音声認識の精度はGAFAMの製品でも静かな場所で明瞭にゆっくり話さなければ6割程度と言われています。
まず間違いなく、そう遠くない未来にはさらに高性能な音声認識が出来るようになるでしょう。

音声認識の活用について
音声認識のカラクリの概要については上記になりますが、その活用方法は多岐に及んでいます。
いわゆる喋る家電のようにあらかじめ録音した音声を繰り返すものは、音声認識技術の産物とは言い難いですが、ボイスコントロール機能がついているのなら話は別です。スマートスピーカーと連携すれば声でスイッチのオンオフが出来ますし、更に発展すればリモコンが不要になる時がくるかもしれません。
下記に機能とその代表的なガジェットやプログラムを紹介します。ほとんどのものが無料で使えるので音声認識がどのようなものか、誰でも簡単に体験できるでしょう。
- 音声認識テキスト起こしソフト(グーグルドキュメント等)
- テキスト起こし機能付きのボイスレコーダー
- AIアシスタント(Cortana、Siri)
- スマートスピーカー(Alexa)
- 読み上げソフト(ボイスロイド等)
- ボーカルソフト(ボーカロイド等)
- ボイスコントロール機能付きガジェット全般(カーナビ他)
- コールセンター業務のサポート
上記の中でも最も簡単に音声認識機能を体験するのならスマホのAIアシスタントで。iPhoneならSiriですし、Android端末ならGoogleアシスタントがインストールされているので実際に話しかけてみると良いでしょう。
またGoogleなどの検索エンジンで音声検索をすれば、喋った言葉が検索窓に打ち込まれます。フリック入力しなくても検索できるので非常に楽です。
スマートスピーカーは話しかけるだけでアクションをしてくれますし、カーナビなどはハンズフリーのボイスコントロールが出来るものが増えました。
また文章作成や何らかのDTM(Desktop Music)創作を行うのなら、ボイスロイドやボーカロイドがおすすめです。SofTalkを始めとして無料の合成音声ソフトもあるので気軽に体験できます。
そして最後ですが、コールセンター業務のような高度な接客対応にも音声認識技術は活用されています。顧客からの第一報をプログラムが受けて顧客の感情分析を行ったり、オペレータと顧客のやり取りを録音すると同時にテキストに起こしてデータとして扱いやすくするサービスがあります。
やり取りをテキスト化できれば聞き直さなくても内容が把握できるので閲覧性がアップしますし、テキストデータとしてまとめた中からテキストマイニング技術で返品や初期不良などの特定のキーワードにタグを付けて抽出してカテゴリ分けする事も出来ます。接客やり取りのテキスト化はまさに音声認識技術のたまものだと言えるでしょう。
チェックしづらい音声をテキストとして管理することでより細かく顧客の声(VOC:Voice Of Customer)を分析できるのです。
このように音声認識機能はテキスト変換機能であり、様々な用途に使われています。
音声認識は今後AIとセットで需要が伸びる技術ですし、フリーの素材も多いので実際にプログラムを組んでみたい人は試してみるのも良いでしょう。
なお、仕事で通話録音をするなら、通話録音サービスの導入がおすすめです。
たとえば「カイクラ」なら、通話が自動で録音されるだけでなく、通話録音のデータを音声・テキストで確認できます。通話中にテキストを検索して過去のやり取りを確認出来たり、後から音声を確認して顧客の感情をくみ取った電話応対につなげたりできるため、電話応対の品質改善につながります。
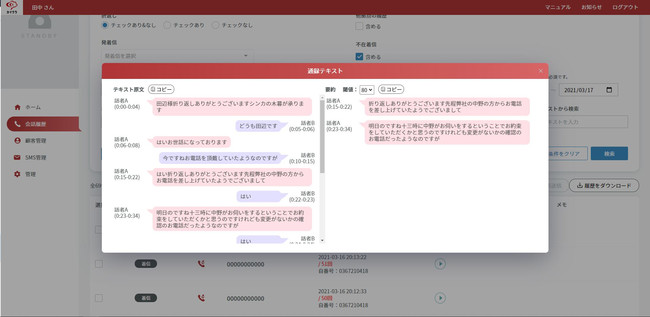
▲カイクラで通話録音データを確認するときの画面イメージ
「電話応対の品質を高めたい!」
「従業員の電話応対の負担を軽減させたい!」
とお考えの方は、ぜひカイクラの通話録音機能がよくわかる資料をご確認ください!
\電話対応の負担が減ったとの声多数!/
カイクラの通話録音機能をチェック
▲無料ダウンロード資料あり

















